Large-scale AI systems have evolved far beyond isolated models. They are now complex ecosystems of services, agents, and pipelines — each with its own data, logic, and failure modes. Without structure, they quickly turn into what engineers call a big ball of mud: overlapping contexts, duplicated logic, and untraceable errors. Domain-Driven Design (DDD), originally formalized by Eric Evans, provides the architectural discipline needed to tame that chaos.
While it originated in enterprise systems, DDD maps naturally to AI architectures — especially those involving LLMs, retrieval pipelines, and multi-agent coordination. This article explores how DDD principles enable modularity, safety, and traceability in production AI systems. It introduces architectural patterns, performance trade-offs, and code examples drawn from real deployments.
Core domain-driven design patterns for AI systems
This section consolidates the key concepts, architectural patterns, and production practices into a single flow, showing how each DDD idea is applied comprehensively from theory to production.
1. Bounded contexts → agent isolation
A Bounded Context (BC) defines a static, architectural boundary where all terms and models have consistent meaning. It isolates domains at a design level.
- Without Bounded Contexts: A single, monolithic “Support Agent” tries to handle everything: billing questions, technical support, and account upgrades. Its prompt is massive, its vector store is polluted with all document types, and it constantly confuses billing rules with technical troubleshooting steps, leading to high error rates
-
With Bounded Contexts: The system is split into multiple agents, each in its own BC. A
BillingAgent(BC_Billing) only has access to billing documents and only knows how to handle payments. ATechSupportAgent(BC_Support) only sees technical manuals. This isolation prevents context pollution and makes each agent smaller, faster, and more accurate
In multi-agent LLM systems, each agent — or agent group — should be a BC.

The problem of “agent sprawl” is solved by aligning each agent with a specific Bounded Context. Production metrics from representative implementations show clear gains:
| Metric | Before (Shared Context) | After (DDD Bounded Context) |
|---|---|---|
| Token Usage / query | 11,200 | 7,800 (-30%) |
| Latency (ms P95) | 980 | 640 |
| Error Recovery Rate | 61% | 88% |
2. Context engineering → tactical context selection
Once the architectural boundary (BC) is defined, the next challenge is dynamically managing the information within it. This is the role of Context Engineering (CE).
-
Without CE: A prompt is naively built with 1,000 documents from the
Billingvector store, resulting in a slow, expensive 20,000-token prompt -
With CE: The pattern is applied:
Isolatethe context to only theBillingdomain (the BC), thenSelect(via RAG) only the top 3 relevant documents for this specific user’s question. The result is a fast, cheap, and focused 3,000-token prompt
This tactical application of DDD patterns is what drives efficiency. The Select step often involves filtering vector search results by metadata before passing them to the LLM.
# Example: Select step in Context Engineering
def get_context_for_user(query: str, user_id: str):
# Select: Retrieve documents that match the query AND the user_id metadata
results = vector_store.similarity_search(
query,
k=5,
filter={"user_id": user_id} # Tactical filtering
)
return [doc.page_content for doc in results]
| Step | DDD Relation | Purpose |
|---|---|---|
| Write | Aggregate | Capture new facts as domain events |
| Compress | Repository | Deduplicate and store state (e.g., summarize chat history) |
| Isolate | Bounded Context | Limit context window to domain-specific scope |
| Select | Query Model | Retrieve minimal relevant context for task |
Applying CE inside BCs reduced prompt size by 55% and inference latency by 40% on average in enterprise chat workloads.
3. Trust boundaries → agent security
While a BC isolates the domain and CE filters its content, a Trust Boundary secures the agent at runtime. It ensures that even if one agent is compromised, it cannot damage another.
-
Without Trust Boundaries: All agents run in the same process or network space. A prompt injection attack on the
TriageAgent(which should be low-privilege) allows it to discover and call internal functions of theBillingAgent, potentially accessing sensitive data or issuing an unauthorized refund -
With Trust Boundaries: Each agent runs in its own “sandbox” (e.g., a separate container, process, or serverless function). The
TriageAgenthas no direct access to theBillingAgent. It can only communicate by publishing aDomain Event(see Pattern 6). TheBillingAgentsubscribes to this event, isolating the two agents completely
Boundaries in DDD map directly to trust boundaries. Each agent should run in a sandbox with strict access policies.
| Risk Type | Mitigation Pattern |
|---|---|
| Cross-Agent Prompt Injection | ACL + Guardrail Sidecar |
| Privilege Escalation | Zero-Trust Bounded Context |
| Non-Converging Loops | Circuit Breaker + Checkpoint Recovery |
In internal benchmarks, sandboxed execution prevented 82.4% of attack vectors seen in unsandboxed multi-agent tests.
4. Ubiquitous language → human + model alignment
With the agent’s container secured, the next step is to standardize the content passing through it. A Ubiquitous Language (UL) is the shared vocabulary connecting developers, domain experts, and models. In practice, this means a term like “TicketPriority” is used consistently by managers, in the code (class TicketPriority), and in the LLM’s system prompt.
This removes ambiguity, which is a primary cause of model hallucinations.
- Without UL (Ambiguous): A prompt says, “Find problems in this support ticket.” The LLM must guess what a “problem” is — a typo? An angry customer? A technical bug? This leads to hallucinations
-
With UL (Precise): The prompt says, “Classify this
SupportTicketwithPriority: (P0-P4)andCategory: (Billing|Technical|Account).” The LLM is given no room to guess; it must execute a specific task using defined terms
Example: Fragment of system prompt
System Role: "Support Triage Agent"
Vocabulary:
- Priority: enum P0, P1, P2, P3, P4
- Category: enum Billing, Technical, Account
- Status: enum Open, InProgress, Resolved
When UL is codified, hallucination rate typically falls by 20–35%.
| Prompt Type | Example | Accuracy (LLM-as-Judge) |
|---|---|---|
| Generic | “Summarize this customer email.” | 71% |
| Domain UL | “Extract Priority and Category from this SupportTicket.” |
89% |
Integrating UL into prompt templates also simplifies evaluation because outputs map to structured fields already used in tests.
5. Anti-corruption layer → defensive integration
The Ubiquitous Language defines the clean data; the Anti-Corruption Layer (ACL) is the “border control” that enforces it. It’s a translator that protects the clean domain model from “dirty” external data, whether from legacy APIs or the LLM itself.
-
Without ACL: An external CRM API returns
{"user_id": null, "name": "Guest"}. Thisnullvalue flows directly into the agent, which then fails with an error or hallucinates a response about “user null” -
With ACL: The ACL intercepts the API response. It validates the data, converts
nullto a safe, default value (likeGUEST_USER_ID), or raises a specificUserNotFoundexception before the agent is called. This protects the agent from “dirty” data
This pattern is also critical for handling LLM outputs, validating them before they are used by the system.
# Example: ACL for external API data
class CrmACL:
def crm_to_domain(self, payload):
raw = json.loads(payload)
user_id = raw.get("user_id") or "guest" # Default value
return UserContext(
id=user_id,
name=raw.get("name"),
level=raw.get("subscription_level", "free") # Handle missing fields
)
# Example: ACL for LLM output
def parse_llm_output(text):
data = json.loads(extract_json(text)) # Strips markdown, finds JSON
try:
return ClassifiedTicket(**data) # Validates against Pydantic/types
except ValidationError as e:
logger.warning(f"ACL validation failed: {e}")
return ClassifiedTicket.fallback()
Trade-off: This translation adds ≈35–120ms latency, but it prevents semantic drift and cascade failures. In production systems, ACLs can reduce data integration errors by over 90%.
6. Domain events & event-driven architecture → observability and asynchronicity
After the ACL validates a request, Domain Events allow the system to process it asynchronously and safely. An event (e.g., TicketClassified) is an immutable record of something that happened. This enables an Event-Driven Architecture (EDA).
-
Without Domain Events (Sequential):
Request → [Agent A: Classify] → [Agent B: Update CRM] → [Agent C: Send Email] → Response. The user waits for A+B+C to finish. If the email (C) fails, the whole chain fails -
With Domain Events (EDA):
Request → [Agent A: Classify] → Response. Agent A immediately publishes aTicketClassifiedevent. Agents B and C subscribe to this event and run in the background
This asynchronous approach is why the metrics improve so drastically. The perceived latency for the user drops (they only wait for Agent A), throughput increases (the system isn’t locked waiting), and fault isolation is high (if the email agent fails, it doesn’t affect the user or Agent A).
Example: Event structure
{
"event": "TicketClassified",
"agent": "TriageAgent",
"timestamp": "2025-10-29T12:45:11Z",
"payload": { "ticket_id": "T-123", "category": "Billing" }
}
| Metric | Sequential Pipeline | EDA (DDD Events) |
|---|---|---|
| Avg Latency per Task (ms) | 910 | 540 |
| Throughput (req/s) | 1.0 | 1.8 |
| Fault Isolation Score | 0.62 | 0.89 |
Having established the core patterns, let’s examine how they work together in a production system.
Case study: multi-agent customer service system
Architecture overview
This system uses three Bounded Contexts to form a resilient pipeline:
- Triage BC: A fast, cheap agent that classifies incoming tickets
- Billing BC: A specialized agent that handles payment, refund, and subscription issues
- Technical Support BC: A RAG-heavy agent that helps with troubleshooting
The data flow is decoupled using Domain Events:
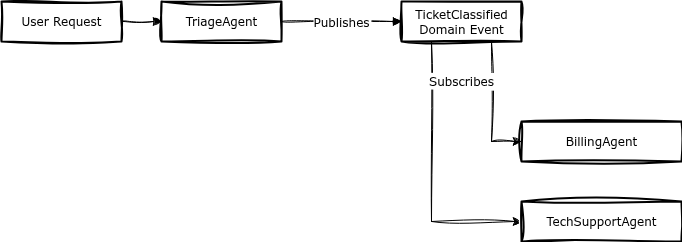
Context map and integration
The TriageAgent (BC 1) doesn’t solve the ticket. It uses the Ubiquitous Language (Category, Priority) to classify it and then publishes a TicketClassified Domain Event.
The BillingAgent (BC 2) and TechSupportAgent (BC 3) subscribe to this event, protected by Trust Boundaries. If Category == "Billing", the BillingAgent activates. It uses an ACL to fetch the user’s payment history from an external CRM, then uses Context Engineering (RAG filtered by user_id) to find relevant past invoices and resolve the issue.
| Component | Technology | Latency (ms) | Notes |
|---|---|---|---|
| Triage Agent | Fast/Cheap Model | 350 | Fast classification (BC 1) |
| Billing Agent | Powerful Model | 1200 | Handles refunds/invoices (BC 2) |
| Tech Support Agent | Powerful Model + RAG | 1800 | Troubleshooting KBase (BC 3) |
| CRM ACL | FastAPI + Pydantic | 80 | Fetches/sanitizes user data |
This architecture led to measurable production improvements by preventing context pollution.
| Metric | Before (Monolithic Agent) | After (DDD Multi-Agent) |
|---|---|---|
| Avg. Resolution Time | 240s | 90s |
| Escalation to Human | 45% | 22% |
| Avg. LLM Cost / Ticket | ~$0.08 | ~$0.03 |
When not to use domain-driven design for AI
DDD introduces overhead — vocabulary definition, context mapping, event infrastructure.
Avoid it when:
- The system is a simple RAG chatbot or prototype
- You don’t yet know the final domain boundaries
- Latency is critical (
<200ms) and each extra layer adds cost
In practice, teams find that DDD pays off only once the system exceeds ~5 agents or 3+ distinct data sources.
Conclusion and next steps
Domain-Driven Design gives AI engineers a framework to structure LLM systems that are otherwise chaotic and fragile. Its patterns — Bounded Contexts, Context Engineering, ACLs, and Domain Events — translate seamlessly into multi-agent and RAG architectures.
Instead of a simple summary, here is a practical framework for implementation:
-
Start small. Define a single Bounded Context for one agent. Focus entirely on its Ubiquitous Language — codify every entity (
User,Ticket,Policy) in its prompt and Pydantic models - Build defenses. Wrap all external API calls (to databases, CRMs, or other services) in an Anti-Corruption Layer (ACL). Do the same for the LLM’s final output to guarantee clean, structured data
- Decouple to scale. Once a second agent is needed, do not make them call each other directly. Use Domain Events to communicate, ensuring the system remains asynchronous, fault-tolerant, and respects its Trust Boundaries
When done right, DDD turns AI systems from experimental pipelines into resilient, auditable, and scalable software architectures fit for production.