Standard RAG pattern: semantic search scoped by metadata (tenant_id, permissions). In production, it causes latency spikes (p99 > 2s) and sometimes no results — even when matching documents exist.
Root cause: HNSW graph is built on vector similarity only. It knows nothing about metadata. Filters don’t create a subgraph — they punch holes in the global graph.
Why filters break HNSW
HNSW connects semantically similar nodes (“contract” ↔ “agreement”) regardless of tenant or permissions. When you apply a hard filter like tenant_id=123, the graph structure stays the same. Search algorithm traverses globally, discarding invalid nodes at runtime.
Problem: if valid nodes are sparse, the greedy search hits dead ends — clusters of semantically close documents that all fail the filter. No valid “bridge” nodes means early termination and poor recall.
Zero results typically occur with post-filtering (global kNN then filter) or when num_candidates is too small for selective filters.
The selectivity trap
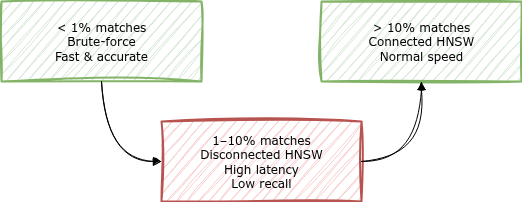
Performance degradation is non-linear. Worst case: filter matches 1–10% of data.
-
< 1% match (low selectivity): At very low selectivity, filtered HNSW may become inefficient; consider explicitly falling back to exact kNN (
script_score) for small filtered sets - > 10% match (high selectivity): Enough valid nodes to maintain graph connectivity. Normal speed
- 1–10% match (the trap): Too sparse for efficient graph traversal, yet too large for default exact kNN thresholds. Latency explodes here
Strategy comparison
| Strategy | Mechanism | Latency | Recall | Trade-off |
|---|---|---|---|---|
| Post-filtering | Global kNN, then filter | Low | Broken | Returns 0 if top-k miss the filter |
| Filtered kNN | Filter during traversal | Variable | Variable | Unpredictable in 1–10% zone |
| Custom routing | Physical shard isolation | Optimal | 100% | Hot shards if traffic/volume uneven per tenant |
| Exact kNN | Linear scan (script_score) |
O(n) | 100% | CPU cost scales with filtered set |
The fix: adaptive strategy
No single approach works for all cases. Switch strategy based on filtered document count.
The ~10k rule: If filter leaves < 10,000 documents, skip HNSW entirely and use exact kNN (script_score).
Why? Order-of-magnitude: exact kNN over ~10k vectors is often tens of ms on modern CPUs and guarantees 100% recall with no graph overhead or random memory access patterns.
Implementation
def adaptive_vector_search(es_client, query_vector, tenant_id, limit=10):
"""
Switches between exact kNN and graph search based on selectivity.
"""
# Check how many docs match the filter
doc_count = es_client.count(index="rag_docs", body={
"query": {"term": {"tenant_id": tenant_id}}
})["count"]
# STRATEGY A: Exact kNN (not ANN) for small sets
# Scales linearly with doc_count, but fast for < 10k docs
if doc_count < 10_000:
return es_client.search(index="rag_docs", body={
"query": {
"script_score": {
"query": {"bool": {"filter": [{"term": {"tenant_id": tenant_id}}]}},
"script": {
"source": "cosineSimilarity(params.qv, 'embedding') + 1.0",
"params": {"qv": query_vector}
}
}
}
})
# STRATEGY B: Routing + HNSW for large sets
# works well if traffic/volume is roughly uniform per tenant
return es_client.search(
index="rag_docs",
routing=tenant_id, # Physical shard isolation
body={
"knn": {
"field": "embedding",
"query_vector": query_vector,
"k": limit,
"num_candidates": 100, # Tuned empirically per corpus; increase as filter becomes more selective
"filter": {"term": {"tenant_id": tenant_id}}
}
}
)
Note: For routing to work, documents must be indexed with ?routing=tenant_id.
Summary
- HNSW doesn’t see metadata. Filters create holes in the graph, not a clean subgraph
- 1–10% selectivity is the danger zone. Too sparse for graph, too large for default exact kNN thresholds
-
The 10k rule: Below 10k filtered docs, exact kNN (
script_score) beats HNSW on speed and recall - Use routing for multi-tenancy. Physical shard isolation keeps per-tenant graphs dense. Works best when traffic/volume is roughly uniform per tenant; otherwise consider bucketing or index-per-tenant