Imagine an AI research agent tasked with “analyzing the risks of a new technology.” On the first iteration, it finds a well-written, authoritative article claiming the technology is perfectly safe. The agent checks its metrics: source authority is high, content is clear, relevance is perfect.
If the architecture conflates Reflection with Evaluation, the agent stops here. It found “good” data. Consequently, it misses critical sources deep in the search results that describe catastrophic failure modes.
This is the “Lazy Agent” pattern. It occurs when we ask the agent “Is the result good?” instead of “Is the research complete?”.
To fix this, we need to carefully define the popular Agent-Critic pattern and not to confuse two distinct critical roles:
- The Reflector (Constructive Critic): Helps improve the current step
- The Evaluator (Judgmental Critic): Delivers the verdict
Mixing these roles leads to structural bias.
The core concept: Reflector vs Evaluator
The root cause of failure is using the same criteria to steer the process and to grade the result.
- Reflector: Operates inside the loop. It drives the research forward. Its goal is Completeness and Consistency. It shouldn’t care if the article is well-written; it only cares if it fills a specific gap in the schema or contradicts previous data. It acts as a “Competitor” to the current findings, actively looking for what is missing or conflicting
- Evaluator: Operates outside (or as a gate for) the loop. It assesses the final artifact. Its goal is Quality and Relevance. It checks if the final compiled answer meets the user’s standards
Visualizing the architecture
The difference is best understood visually.
The Trap (Mixed Concerns): Here, the Reflector and Evaluator are effectively the same entity or share the same goal. The agent stops as soon as it finds “good enough” information, prone to confirmation bias.

The Solution (Separated Concerns): Here, the Reflector acts as an architect ensuring the structure is built, while the Evaluator acts as a separate quality gate. The agent stops only when the structure is complete. Quality is checked only afterwards.
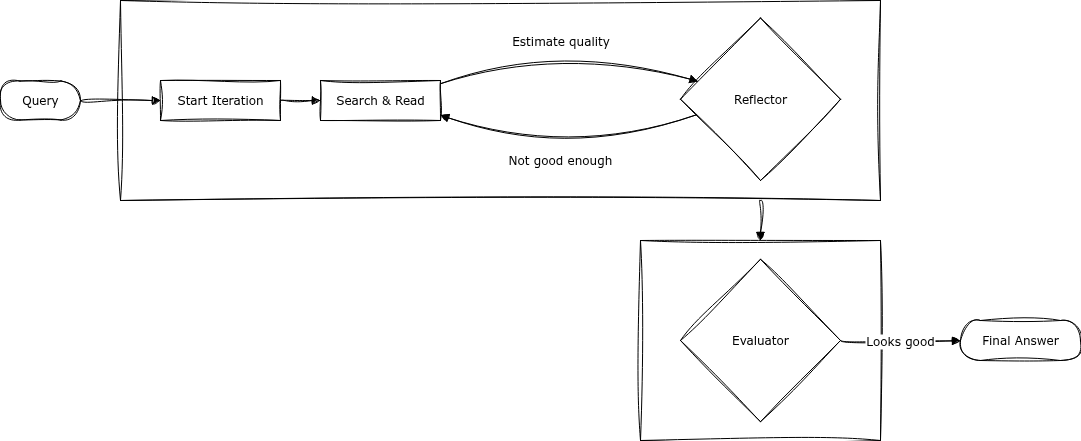
The reflector: Engine of curiosity
The Reflector is a generative mechanism. It analyzes the history of actions to produce the next instruction. It answers: “Do I have enough information to form a comprehensive view?”
It relies on a Canonical Model — a schema of what the answer should look like (e.g., “Pros”, “Cons”, “Market Data”, “Competitor View”).
Key logic:
- Gap Analysis: “I have the ‘Pros’, but the ‘Cons’ field is empty.”
- Contradiction Detection: “Source A says X, Source B says Y. I need a third source to resolve this.”
- Perspective Taking: “I have the CEO’s view. I need the Expert’s view.”
Implementation (Logic-focused):
def reflection_step(state: AgentState, schema: CanonicalModel) -> Decision:
"""
Decides ONLY based on data presence and consistency.
Does NOT judge source authority or writing style.
"""
# 1. Check for 'holes' in the data structure
missing_fields = schema.get_empty_fields(state.collected_data)
# 2. Check for conflicting facts (e.g., different dates, pricing)
contradictions = detect_contradictions(state.collected_data)
# 3. Decision Logic
if missing_fields:
# Generate query specifically for the missing part
return Decision.CONTINUE(
query=f"Find information about {missing_fields[0]}",
reason="incomplete_model"
)
if contradictions:
# Generate query to resolve the specific conflict
return Decision.CONTINUE(
query=f"Verify exact figures for {contradictions[0].topic}",
reason="resolving_conflict"
)
# Only stop if the model is full and consistent
return Decision.STOP(reason="model_complete")
The evaluator: Quality gate
The Evaluator is a discriminative mechanism. It runs after the research loop proposes a “complete” model. It answers: “Is this answer good enough for the user?”
Key metrics:
- Source Authority: Are the domains trusted? (e.g., arxiv.org vs random blog)
- Relevance: Does the answer actually address the user’s prompt?
- Hallucination Check: Do the citations actually support the claims?
Implementation (Logic-focused):
def evaluation_gate(final_data: dict, original_query: str) -> EvaluationResult:
"""
Scalar assessment of the final artifact.
"""
scores = {
# Did we answer what was asked?
'relevance': measure_relevance(final_data, original_query),
# Are the sources credible?
'trust': measure_source_authority(final_data['sources']),
# Is the content diverse (bias check)?
'diversity': measure_perspective_diversity(final_data)
}
weighted_score = calculate_weighted_average(scores)
if weighted_score > THRESHOLD:
return EvaluationResult(passed=True, score=weighted_score)
else:
return EvaluationResult(
passed=False,
score=weighted_score,
feedback=generate_critique(scores) # Instructs what to fix
)
The canonical model: The bridge
The Canonical Model is the contract between Reflector and Evaluator. The Reflector tries to fill it; the Evaluator checks the quality of the filling.
For a “Compare X vs Y” task, the model enforces neutrality:
comparison_model = {
"entity_a": {"features": ..., "pricing": ..., "limitations": ...},
"entity_b": {"features": ..., "pricing": ..., "limitations": ...},
"direct_comparison": "required",
"consensus_view": "required",
"contrarian_view": "required" # Forces search for opposing opinions
}
By making contrarian_view a required field, you force the Reflector to explicitly search for criticism, preventing the agent from stopping after finding just positive articles.
Why mixing them fails (The math of bias)
When the Reflector uses Evaluation metrics (quality) to decide stopping, you introduce Selection Bias.
Mathematically, the probability of stopping becomes dependent on the “goodness” of the current find:
\[P(\text{stop}) \propto Q(\text{current\_data})\]This means the agent is statistically likely to stop at the first “good looking” local maximum, ignoring the global truth.
Correct Approach: Stopping should depend on the Saturation of the schema, independent of the Quality of the content:
\[P(\text{stop}) = f(S_{\text{completeness}}, S_{\text{consistency}})\]Evaluation is then applied as a post-hoc filter.
Production implementation: LangGraph architecture
This separation isn’t just theoretical — it’s implementable in production systems. Here’s how to structure it using LangGraph:
from __future__ import annotations
from typing import Optional, Literal, Dict, Any
from pydantic import BaseModel, Field
from langgraph.graph import StateGraph, START, END
class ResearchState(BaseModel):
query: str
collected_data: Dict[str, Any] = Field(default_factory=dict)
iteration: int = 0
should_continue: bool = True
evaluation_result: Optional[dict] = None
def build_research_graph():
"""
Separation of concerns:
- reflection controls the loop (completeness/consistency)
- evaluation runs only when loop stops (quality gate)
"""
g = StateGraph(ResearchState)
g.add_node("research", research_node)
g.add_node("reflection", reflection_node)
g.add_node("evaluation", evaluation_node)
g.add_edge(START, "research")
g.add_edge("research", "reflection")
def route(state: ResearchState) -> Literal["research", "evaluation"]:
return "research" if state.should_continue else "evaluation"
g.add_conditional_edges("reflection", route, {
"research": "research",
"evaluation": "evaluation",
})
g.add_edge("evaluation", END)
return g.compile()
def research_node(state: ResearchState) -> ResearchState:
"""Execute search, collect data"""
new_data = execute_search(state.query)
merged = {**state.collected_data, **new_data}
return state.model_copy(update={"collected_data": merged})
def reflection_node(state: ResearchState) -> ResearchState:
"""Check completeness against canonical model"""
missing = canonical_model.get_missing_fields(state.collected_data)
contradictions = detect_contradictions(state.collected_data)
should_continue = bool(missing or contradictions)
new_query = (
generate_query_for_missing(missing[0])
if missing else state.query
)
return state.model_copy(update={
"should_continue": should_continue,
"iteration": state.iteration + 1,
"query": new_query,
})
def evaluation_node(state: ResearchState) -> ResearchState:
"""Assess quality of complete data"""
scores = {
"relevance": measure_relevance(state.collected_data, state.query),
"source_quality": assess_sources(state.collected_data),
"bias_score": detect_bias(state.collected_data),
}
passed = sum(scores.values()) / len(scores) > 0.7
return state.model_copy(update={"evaluation_result": {"scores": scores, "passed": passed}})
The key architectural decision: reflection_node sets should_continue based solely on structural completeness, while evaluation_node runs only after the loop terminates and assesses quality metrics.
Monitoring: Detecting system failures
Production systems need metrics to detect when Reflection or Evaluation breaks.
Reflection failure signals
Loop Drift (Agent stuck repeating actions):
reflection_metrics = {
# Average number of research iterations before completion
# Calculated: sum(iterations_per_request) / total_requests
'avg_iterations': 2.3,
# Percentage of requests that hit max_iterations limit
# Calculated: requests_hitting_limit / total_requests
'timeout_rate': 0.05,
# Number of times agent executed identical action consecutively
# Detected by comparing action hashes in sliding window
'repetition_threshold_hits': 12
}
# Alert if timeout_rate > 0.15
# → Canonical model has unrealistic required fields
Premature Stopping:
completion_audit = {
# Percentage of research sessions stopping after just 1 iteration
# Calculated: single_iteration_completions / total_requests
'stopped_at_iteration_1': 0.23,
# Average count of required fields still empty when stopping
# Calculated: sum(empty_required_fields) / total_stopped_requests
'avg_missing_fields': 1.4
}
# Alert if stopped_at_iteration_1 > 0.3
# → Reflection incorrectly considers incomplete data "complete"
Evaluation failure signals
False Positive (Passes bad content):
evaluation_metrics = {
# Percentage of answers passing evaluation gate
# Calculated: passed_evaluations / total_evaluations
'pass_rate': 0.87,
# Percentage of passed answers rejected by users (thumbs down, edits)
# Tracked via user feedback events
'user_rejection_rate': 0.31,
# Pearson correlation between evaluation scores and user ratings
# Calculated on sample of 100+ user-rated responses
'correlation': 0.42
}
# Alert if correlation < 0.6
# → Evaluation metrics don't predict user satisfaction
False Negative (Rejects good content):
retry_metrics = {
# Average number of reflection-evaluation cycles before final acceptance
# Calculated: sum(retry_counts) / successful_requests
'avg_retry_count': 4.2,
# Percentage of eventually successful requests after multiple retries
# High value + high avg_retry_count = evaluation too strict
'final_success_after_retries': 0.65
}
# Alert if avg_retry_count > 3
# → Evaluation thresholds too strict, wasting compute
Diagnostic dashboard
Track these metric pairs to identify which component broke:
| Symptom | Broken Component | Fix |
|---|---|---|
High timeout_rate + Low pass_rate
|
Canonical model too strict | Relax required fields |
High pass_rate + High user_rejection_rate
|
Evaluation too lenient | Tighten thresholds |
High stopped_at_iteration_1 + High avg_missing_fields
|
Reflection logic error | Fix completeness check |
High avg_retry_count + Low timeout_rate
|
Evaluation too strict | Lower thresholds |
Summary: Design rules
- Separation of Concerns: Never let the component searching for data decide if the data is “good.” Let it only decide if the data is “there”
-
Opposing Criteria:
- Reflector criteria: “What is missing? What doesn’t add up? Who disagrees?” (Drive for entropy reduction)
- Evaluator criteria: “Is this authoritative? Is this safe? Is this precise?” (Quality control)
- The Schema is Important: Use structured Canonical Models to drive Reflection. An abstract “search until done” instruction leads to lazy agents
- Fail-Fast vs Fail-Late: The Reflector should fail fast (iterate quickly). The Evaluator should fail late (reject the final product), triggering a focused repair loop
By defining this separation, we move from agents that “hallucinate success” to agents that rigorously construct answers.